Trying to make a 2-column list which scrolls on demand, and doesn't break the layout when the scrollbars appear is rather fiddly in CSS.
This solution uses a UL, where the LI elements are set to float left, and the width of each is set to 50%. Note that I've used the CSS3 property box-sizing (or -webkit-box-sizing) to make the 50% widths include the border and padding. Without this the total width of two 50% elements with a border adds up to more than 100% and the layout breaks.
Note that the height of each element must be set explicity.

Tuesday, 30 November 2010
Monday, 29 November 2010
Simple method of horizontally centering a DIV of unknown width
Centering in CSS is always a pain. If you are just centering text, or you are using (god forbid) IE6 then you can simply use the text-align property. If you are centering something of a known width, it's easy too, just set margin-left and margin-right to 'auto' and all is good. However, if you don't know how wide the element is going to be, for example, you have an element that expands to fit some text pulled from a database, it's a bit tricker.
There are loads of hacks around of varying reliability and complexity, but the simplest method I have found yet is the following.
That's it. The fact that the inner div is set to inline-block means it picks up its parent's setting of text-align to center itself. Is kinda wierd, but works on all the browsers I've so far tested.
There are loads of hacks around of varying reliability and complexity, but the simplest method I have found yet is the following.
- The outer div is set to text-align: center
- The inner div is set to display: inline-block
That's it. The fact that the inner div is set to inline-block means it picks up its parent's setting of text-align to center itself. Is kinda wierd, but works on all the browsers I've so far tested.
Thursday, 25 November 2010
Setting permissions on Amazon AWS S3 buckets using S3cmd
Calvium stores virtually all of its toolkit data on S3 servers. We often find ourselves using Cyberduck to manually upload and download files when required. One thing that is a pain though is setting permissions. Cyberduck doesn't appear to allow you to set the permissions on all files within a folder recursively. When you have a lot of files this can be a real pain. Happily s3cmd comes to the rescue! s3cmd is a third-party (e.g. not created by amazon) command line client for S3 which runs on linux, unix, and also MacOSX. It may compile on Windows, I haven't tried.
The above commands also work on folders within buckets, or on individual files (the --recursive option is not required in this last case). As you can imagine there are many more options (type s3cmd --help to see more help).
By default, new buckets will list all of the files within them. This isn't usually a good idea though, as it makes it very easy indeed for someone to scape all the content of your site. The command above just omits the --recursive option. For new buckets it's probably best to run command (1) before (3) so that your files are actually readable.
1) Make everything in a bucket public (e.g. everyone has read access)
s3cmd setacl s3://myexamplebucket.calvium.com/ --acl-public --recursive
2) Make everything in a bucket private (e.g. accessible only to the creator)
s3cmd setacl s3://myexamplebucket.calvium.com/ --acl-private --recursive
The above commands also work on folders within buckets, or on individual files (the --recursive option is not required in this last case). As you can imagine there are many more options (type s3cmd --help to see more help).
3) Disable Directory Listing in a bucket
s3cmd setacl s3://myexamplebucket.calvium.com/ --acl-private
By default, new buckets will list all of the files within them. This isn't usually a good idea though, as it makes it very easy indeed for someone to scape all the content of your site. The command above just omits the --recursive option. For new buckets it's probably best to run command (1) before (3) so that your files are actually readable.
Wednesday, 24 November 2010
Mac OSX - Making the finder search work (almost) properly
One thing that has irritated me for a long while is that the search box in the top right of the finder window in mac osx defaults to searching my whole mac, and not the folder I'm currently looking at. If I wanted to search the whole Mac I'd use the Spotlight search wouldn't I Mr Jobs?
Anyway, I just discovered that it's possible to change this behaviour. Open Finder, go to the menu and choose Finder / Preferences / Advanced, and select 'When performing a search: Search the current folder".
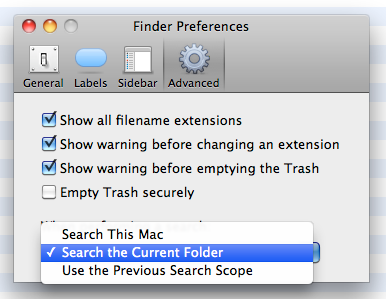
So much better!
Now I just need to find a way to make it search by FIle name and not file contents.
EDIT: Apparently there is no way of defaulting to search by file name in Snow Leopard. However, in finder you press CMD-SHIFT-F, then it will put the cursor in the search panel, and set it to search by file name. Not too bad at all!
Anyway, I just discovered that it's possible to change this behaviour. Open Finder, go to the menu and choose Finder / Preferences / Advanced, and select 'When performing a search: Search the current folder".

So much better!
Now I just need to find a way to make it search by FIle name and not file contents.
EDIT: Apparently there is no way of defaulting to search by file name in Snow Leopard. However, in finder you press CMD-SHIFT-F, then it will put the cursor in the search panel, and set it to search by file name. Not too bad at all!
Disabling file cacheing on the server using htaccess
Recently I've been testing our web app tools locally using MAMP. These apps eventually end up making changes to files in the file system. I've been finding however that the changes are regularly not picked up in the browser until I empty the browser cache. This is kind of irritating as you can imagine.
The solution was to define a .htaccess file in the directory containing the editable content files that prevents browser cacheing. Obviously make sure this is only used locally during testing! This also requires the Apache module mod_headers - MAMP 1.9.4 (and probably other versions too) include this by default.
Adapted from here:
http://www.askapache.com/htaccess/using-http-headers-with-htaccess.html
The solution was to define a .htaccess file in the directory containing the editable content files that prevents browser cacheing. Obviously make sure this is only used locally during testing! This also requires the Apache module mod_headers - MAMP 1.9.4 (and probably other versions too) include this by default.
# when in local mode, never caches anything in this folder.
<IfModule mod_headers.c>
Header unset ETag
Header set Cache-Control "max-age=0, no-cache, no-store, must-revalidate"
Header set Pragma "no-cache"
Header set Expires "Wed, 11 Jan 1984 05:00:00 GMT"
</IfModule>
Adapted from here:
http://www.askapache.com/htaccess/using-http-headers-with-htaccess.html
Wednesday, 17 November 2010
Zebra Striping Tables with Pure CSS
I've seen quite a lot of tutorials for this effect that use Javascript, particularly jquery.
You can do it with pure CSS though using the handy :nth-child(odd) and :nth-child(even) selectors in CSS3.
This is a fragment from a javascript errors dialog I created for an online code editor for Calvium.com
You can do it with pure CSS though using the handy :nth-child(odd) and :nth-child(even) selectors in CSS3.
This is a fragment from a javascript errors dialog I created for an online code editor for Calvium.com
Amazon AWS S3 Buckets: Safely Granting 3rd Party Sites Access
Some services, for example unfuddle.com have a neat feature where they can automatically back everything up to an S3 bucket in case of issues. This morning unfuddle went down for a while, so when it came back up I thought it would be a good idea to finally set this up.
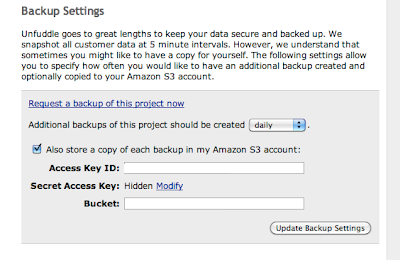
Unfuddle asks for the 'access key id' and 'secret access key' in order that their scripts can write direct to your bucket. This is great, but armed with both those keys an attacker can easily access ALL of the buckets associated with that account. Our main account has potentially sensitive data in some of the buckets, so there is obviously no way we'd share the keys to that account with anyone.
Instead, what we can do is to create a completely new AWS account, and from the main account grant access to the new account ONLY to the bucket that'll contain the unfuddle backups. Note that you do not need a credit card number to do this, as the new account will not 'own' any of its own buckets. Also note that usage charges for the backup bucket will be applied to the main account.
Here's how: (note this tutorial requires Cyberduck, a free S3 and FTP client).

Unfuddle asks for the 'access key id' and 'secret access key' in order that their scripts can write direct to your bucket. This is great, but armed with both those keys an attacker can easily access ALL of the buckets associated with that account. Our main account has potentially sensitive data in some of the buckets, so there is obviously no way we'd share the keys to that account with anyone.
Instead, what we can do is to create a completely new AWS account, and from the main account grant access to the new account ONLY to the bucket that'll contain the unfuddle backups. Note that you do not need a credit card number to do this, as the new account will not 'own' any of its own buckets. Also note that usage charges for the backup bucket will be applied to the main account.
Here's how: (note this tutorial requires Cyberduck, a free S3 and FTP client).
- Make a new email address such as aws-myproject@example.com.
- Go to amazonaws.com, and sign up for a new account using the new email addres
- When you are logged in, choose 'account' from the main menu, then 'security credentials'
- In the passwords file, record the email you used, and the 'access key ID' and 'secret access key'.
- Log in to your main AWS account using Cyberduck.
- Create a new bucket, called, for instance myproject.example.com
- Right-click the new bucket, click Info and click the Permissions tab
- Click the cog icon, then Amazon Customer Email address.
- Type aws-myproject@example.com. In the right column, choose WRITE
- Repeat the last two steps, but choose READ in the right column. (this step is optional)
- Your user now has read and write access to the myproject.example.com bucket.
Note that if you try to use Cyberduck to view the S3 account for the aws-myproject@example.com it will fail. This is because Cyberduck uses s3 features that assume that the account is signed up for S3 services (which requires a credit card). For the same reason using s3cmd (command-line tools for S3 acccess) to list all buckets will also fail. However, using s3cmd to view the contents of the specific bucket we have granted access to will succeed (for example s3cmd ls s3://myproject.example.com will work)
This tutorial assumes unfuddle, but will work for any third-party cloud service that wants to read or write to S3 buckets.
Thanks to Tom & Richard of Calvium for the idea, and for their help setting this up.
EDIT: 16-02-2011. This currently doesn't work properly on unfuddle due to their system failing in the same way that cyberduck does. Am in contact with them to sort it out
Monday, 8 November 2010
jQuery: Working with radio buttons
Each time I need to use radio buttons in jQuery I need to look it up - here's the best way to use them I've found so far..
<form id="my-form">
<input type="radio" name="group-name" value="value1">
<input type="radio" name="group-name" value="value2">
</form>
// set up the initial value (theValueToSet)
var $log = $("#my-form input[name=group-name]"); // #my-form is optional, but speeds up the search
$log.filter("[value="+theValueToSet+"]").attr("checked","checked")
// do something when the value is changed..
$log.change(function() {
var selectedValue = $(this).val();
});
// getting the value out again later on
var value = $("#my-form input[name=group-name]").val();
Subscribe to:
Comments (Atom)